Trivial
Trivial
Trivial
This is a periodic reporting requirement, similar to the bi-monthly reports but bigger.
Martin says this this report should be a synthesis of all the bi-monthly reports already submitted. He makes the point that this is a management activity rather than a scientific one, so scientific partners should not be heavily loaded by this work.
A long discussion follows about exactly what figures Mikko is going to need in order to prepare the financials for this report. I assume that all this will be summarised in email, so I am not taking notes.
In the review of deliverables and milestones, two of our jobs are relevant, both milestones.
Mikko on financial reporting: nothing new here, I think.
[Lots of discussion of reviewers' comments. Nothing new except what I dicuss below.]
One of the reviewers, who is clearly a Semantic Web believer, seems to think that Alvis should use RDF. What for? This is not clear, in fact it appears that he hasn't made any actual proposal, and just thinks that RDF is a good thing that should be used, well, everywhere. Unsurprisingly, I think this is stupid. Karl agrees, but otherwise the general sentiment of the meeting seems to be that we may as well give the reviewer what he wants ... if he can figure out what the heck that is.
[Recap of four layer architecture: transport layer, structured overlay network, document and content management, retrieval models.]
[Summary of how ``inverted files'' are used in conventional IR].
In a P2P distributed system, each peer is responsible for certain terms and their postings lists. Query terms are forwarded to the responsible peer, which returns the corresponding postings list. The association of a given query term with a particular peer is done using some kind of magic hash function with load balancing and suchlike.
On problems with this approach is that postings lists can be very long (e.g. for ``the''). An EPFL study has shown that this is not feasible. The proposed solution is to limit the lengths of postings lists by combining terms. A threshhold size is created defining the longest acceptable postings list. If the list for a given term becomes larger than this, then its posting list is discarded and instead a lists is created for the combination of the term with one or more others. A set of n such terms indexed in conjunction is called a key. This is HDK indexing.
How do you decide which terms to combine into keys? One clue is to use terms that appear in the same context in a document. [Note: this requires knowledge of an entire corpus.] This limits the number of keys to be linearly related to the number of terms.
Warning: dark arts ahead. What happens if you search for a combination of terms that is too common to have a postings list, such as ``britney spears''? The proposed solution is ``distributional semantics'': an association matrix makes probabalistic connections between terms. This is used to find terms that are likely to be related to term1 and term2. [My comment: huh?]
Important action point. Martin agrees that we should be able to play with this if we're going to sign up to the approach. Accordingly, Wray will send him a selection of about 7000 randomly chosen Wikipedia articles which he will roll into an HDK index that we can all search over the web. That way, we can reassure ourselves that this really does work, using real queries.
EPFL's presentation includes graphs showing impressive characteristics of the HDK approach, indicating query recall very similar to that of simple single-term indexing and postings bandwidth between 1/10 and 1/5 as great.
Future work includes:
Claire or Adeline asked how this approach integrates the probability values calculated by Wray's module. The reply is complex (I don't really understand it) and doesn't seem to be convincing people.
I asked how they see the WP3 indexing engine contributing to the EPFL framework. The answer was even less convincing, and amounts to ``it doesn't matter, we'll find a way to wedge it in somewhere around the edges''.
[Later:] Unbelievable. Just unbelievable.
Tenatative conclusion for the demo in March: we should just demonstrate Zebra's ability to quickly index and search large collections of documents. Most usefully, these will be documents generated by the NLP, including linguistic markup from WP5 and document probability measures from WP2. We should let EPFL do their own demonstration.
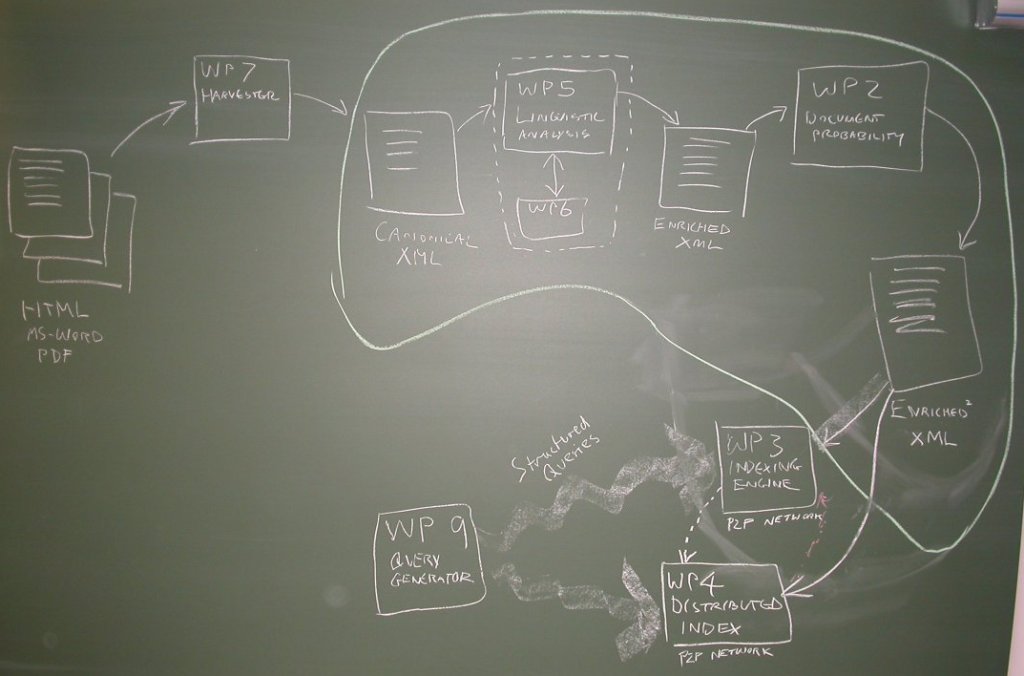
The WP7->WP5/6->WP2 pipeline that produces enriched XML is considered to be atomic. Then what happens to the XML that's produced? It can be passed into either one of two competing P2P networks. One of them uses a single distributed index, implemented by WP4's P2P techniques. The other uses a P2P network of autonomous nodes implemented by WP3, trickling queries between them. Both of these networks can also be queried using the same protocol - probably a simple HTTP GET query. Then:
This means that the project is doing valuable competitive research, that it can investigate the interactions between different P2P approaches. It also gives Alvis a backup plan, so that if either P2P approach turns out to perform unsatisfactorily, the success of the other would constitute the success of the project.
Here is a photo of the illustration that I drew on the blackboard.
Not really relevant to us.
Martin presents an elaboration of the architecture diagram that I presented yesterday. It's ... complicated. But I think it's all presentational complexity deriving from an academic perspectic, rather than intrinsic complexity that we have to actually implement.
We still owe Mikko a Form C and an Audit Certificate.
--
{kind=link}